The Build Pipeline
The build pipeline describes the process by which new code makes its way out to a production environment. One may even consider a developer building code on his or her local machine and manually deploying it to a server a primitive build pipeline. While this approach may work well for small or non-critical operations, it is insufficient for most professional work. Whether you're working in the hottest new startup or for a larger company, defining an effective build pipeline and streamlining your deployment process is of utmost importance. While this article will omit implementation details, I will go through a thorough explanation of each step and why it's important and how it improves the lives of developers and overall stability of products.
Continuous Integration, Continuous Delivery
Before I delve deeper into build pipelines, I want to briefly familiarize the audience with continuous integration, continuous delivery (CICD). This concept has been around for several years, but I have heard grumbles about this from colleagues. In summary, the idea is that every commit to the mainline (i.e. usually master branch in git) is built and continuously tested (i.e. continuous integration) and when all of those tests pass, the code is then deployed immediately to production (i.e. continuous delivery).
Many people claim that such a system sounds good in theory, but always fails in practice. Well, I happen to have it on good authority (i.e. personal experience) that this sentiment is categorically false. Yahoo/Flurry/Oath have been using CICD for some time now and the method works very well. In fact, it saves a lot of headache and avoids many mistakes or potential outages which occur from manual deploys or even gated deploys (the discussion of distinction between the two may be for another time, however).
While I am a proponent of CICD and will center our build pipeline discussion around this idea, I must admit that it does front-load a lot of the work. That is to say, CICD requires a larger upfront investment cost than traditional means of operations and code deployment. While the infrastructure can theoretically be built over a period of time, it is best to have all of the infrastructure in place before releasing your product.
In this way, you will be able to allocate sufficient resources into building a robust system. If the product is released before the CICD infrastructure has been properly laid out, it's very easy to get side tracked into focusing only on improving the product rather than process of releasing changes. This ultimately ends up wasting a significant amount of developer resources. Please note, when I say infrastructure I really mean your deploy scripts or something similar. I expect most companies will not be rolling their own CICD solution and instead use something like Jenkins or Screwdriver.
tl;dr. CICD is great but you need to give it the upfront investment it deserves when you're building a new system. Ensure that the infrastructure is in place (even if not all the testing is finished depending on how fast and loose you're playing) before officially launching your product. See cert
Philosophy of the Build Pipeline
Let's move on and discuss a bit more deeply about the ideas of our build pipeline. In summary, an effective build pipeline should have at at least 3 phases:
- Unit testing phase. Often times this is the first step in your build pipeline. Unit testing runs before you've packaged your code for shipping. In the unit testing phase, all unit tests should be run for the codebase that is actively being built. Similarly, you can run "local" integration-style testing (with mocks and so forth) if you have them in this phase.
- Smoke testing phase. If you have the resources, you should have a non-production environment which looks nearly identical to your production environment (though probably at much smaller scale). It's even possible to run this environment on a single box if the services won't conflict with each other. Similarly, you would not necessarily use production data in this environment. Most importantly, this environment runs real services. At this point you should run a set of smoke tests which will effectively test basic integration of your services.
- Integration testing phase. The final essential component of a build pipeline is the integration testing phase. This phase should deploy your services to a production or production-like environment and verify a full suite of integrations on your production system. With a proper test suite, performing this step enables the developers to find the vast majority of issues before they become customer-facing.
While we have discussed 3 primary components of a build pipeline, this often represents the bare minimum. Build pipelines can be arbitrarily complex and can even include triggering up- or downstream dependencies. No matter how complex your build pipeline dependency graph becomes, these 3 phases should be present in some capacity.
A More Sophisticated Build Pipeline
With the 3 components listed above, we will now go through an example of a more sophisticated build pipeline. While not overly complex, this is a realistic pipeline that one could use to deploy their own code. Again, implementation details are omitted, but the core concepts remain.
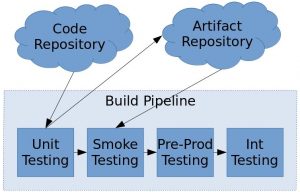
A brief explanation of the diagram above follows:
- Code repository. This is where your raw source code lives. It is likely a version control system (VCS) such as git, svn, or otherwise.
- Artifact repository. The artifact repository is where your compiled code packages live. For instance, this code be a local artifactory of NPM repository.
- Unit testing. The unit testing phase is described above. It first pulls in code from your repository, then it runs and verifies its unit testing. Upon successful completion, it will upload a compiled artifact to the artifact repository and trigger the smoke testing job.
- Smoke testing. Smoke testing is also described as above. It should deploy the latest artifact from the artifact repository and run a series of smoke tests. Upon successful completion, it can optionally tag an artifact as the last smoke verified artifact (to better ensure you never accidentally deploy untested code) and then trigger the pre-prod environment.
- Pre-Prod Testing. The pre-production environment is an "extra" production box. Namely, one that is either taken out of rotation or a dedicated host (or set of hosts) that are connected to production services but are never actually visible to the outside world. This environment tests your current production setup against the code you wish to deploy (but before you actually deploy it). It should pull the latest available service artifact (unless you tagged an artifact as latest smoke verified) and run a series of typical production-style integration tests. Upon successful completion, it should tag its artifact as the latest verified artifact and trigger the int testing job.
- Int Testing. Finally, the integration testing is the last step in this build pipeline. Assuming you have a cluster of hosts running your services (read: this is good practice for redundancy) it will take a subset of those hosts out of rotation (OOR); this ensures that the service stays fully available to customers while the deployment is on-going. For the OOR hosts, it will deploy the latest verified service artifact and wait for the service to come up. When the service is ready, it runs the set of integration tests on those boxes. After those boxes have been verified successfully, it will return the OOR hosts back to the production rotation and then take out a different subset. This process repeats for however many distinct subsets exist. That is, if you deploy to a single box at a time and have a 5 box cluster, then this step will repeat 5 times or once per box.
By the end of this build pipeline, your newly built and tested code is fully deployed to production if all steps pass. If at any point the tests fail, the build stops at that point and does not proceed further in the build pipeline. It is important to recognize that during the final integration testing phase that this could, in fact, leave the subset of boxes OOR if the tests fail. As a result, the number of boxes deployed at once should be an acceptable number of failed hosts for your application.
Conclusion
While more complicated build pipelines than we've discussed exist, build pipelines do not need to be complex to be useful. However, there exists a minimum set of functionality they must test for effectiveness. Even the simplest of build pipelines can improve developer productivity and reduce operations mistakes. By simply automating the testing process alone, we've avoided mistakes of human error (i.e. forgot to run a test, skipped a test intentionally, didn't follow deployment steps properly for service, etc.) and ensured that our tests are always properly run. Not only does this avoid error, but it also frees up engineering resources to perform other useful work.
Above all, if you do not currently have a build pipeline, you should consider designing one and implementing it. Not only will it improve the lives of your engineers, it will provide confidence to all of your business units. A proper build pipeline allows everyone in your organization to feel confident about code quality for user-facing products.
