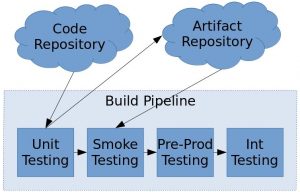
Integration Testing
Integration testing is an important part of any production system. Whether it is automated, performed by a QA team, or done by the developer him- or herself, it is essential that all the product bits are verified before revealing the result to the customer. Generally speaking, integration testing is simply running a set of tests against a production-like environment. That means you remove any testing mocks you may have in place and observe the actual interactions between the various services which make up your product.
Development Issues with Complex Systems
The larger your systems scale, the more difficult it is to test them all on the same box. This simple fact comes from increasing system complexity; as your user-base grows, you utilize more resources, and your software architecture begins to span multiple machines. For instance, if you're building a lot of microservices, then each of these needs to be stood up and configured properly to work on your local box. Now each developer needs to duplicate this work for his or her own local setup.
Eventually, maintaining your local "full-integration" development environment becomes unwieldy and possibly even more difficult to manage than production (due to dependency issues, etc.). What this ultimately means is that developers kill this environment entirely. They write their code and unit tests and then just ship it off to the build pipeline. After waiting a period of time, their code should show up in an "pre"-production environment for a full-scale integration test. At this point, they identify if there are any glaring bugs in their code or some other additional oversight.
The problem here is that this process is inefficient. Not only is this slow, but when you share an environment for testing, it is common that multiple changes are deployed at once. As a result, it can sometimes become unclear which change is causing issues. Now let me make myself clear: you should have an environment that integrates all the latest changes before they go to production. This environment will protect you from a plethora of additional production issues (i.e. logically incompatible changesets), however, it is not the best way for developers to test their code. Developers should have tested their code thoroughly before pushing it to the environment that is going to certify it and send it to production.
Docker Compose
Well, this sure seems like a predicament. I just mentioned that for large services it often becomes incredibly difficult to maintain a local version of your complete system. While this is true, we can significantly reduce the burden with docker compose. Docker compose is a tool for managing multi-container Docker applications. In short, you can define an arbitrary system composed of many containers. This tool provides a perfect foundation for us to reproduce a small-scale version of production that can be run entirely locally.
Using Docker compose should be trivial if you're already deploying your services using Docker containers. If not you should first create Docker images for all of your services; while this is labor intensive, you and your team members can reuse these images in the future.
Our Example
Now that we understand the problem and our tools for solving it, we will work through an example. Below is a diagram describing our scenario.
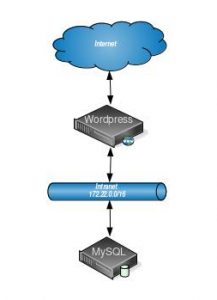
In summary, we have a basic WordPress setup with a few minor tweaks. Rather than hosting both MySQL and WordPress on the same box, we have separated the concerns. Our WordPress application server is accessible on the open internet and our internal network. Our MySQL server, on the other hand, lives on a separate box only accessible on our intranet to prohibit anyone from external requests directly to the database. This example illustrates how one may naturally expand their services. Similarly, you could generalize this concept to arbitrarily complex networks.
Assuming this is the network we want to model with docker compose, let's take a look at configuration file below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
version: "3.2" services: wordpress: image: wordpress expose: ["80"] restart: always depends_on: - mysql-box networks: backend: ipv4_address: 172.22.0.3 external-net: ipv4_address: 172.32.0.5 mysql-box: image: mysql environment: MYSQL_ROOT_PASSWORD: root restart: always networks: backend: ipv4_address: 172.22.0.5 networks: external-net: ipam: config: - subnet: 172.32.0.0/16 backend: internal: true ipam: config: - subnet: 172.22.0.0/16 |
Without delving too deeply into the configuration format, the most notable information in this configuration file is the virtual networking. We have two different networks-- external-net and backend-- which correspond to Internet and intranet in our diagram, respectively. These networks provide the separation of concern as we had designed above. However, more important than the implementation details is the concept which this represents. Namely, we can specify the images, settings, and networking configuration for our docker containers and reuse this file everywhere. Once this file has been built once, it can be shared with the entire team making local integration testing accessible again. With a little maintenance for the addition of new services, this file can become a more faithful representation of your production environment for developers.
Conclusion
We have briefly discussed a major impediment to local integration testing today; most notably, the growing complexity of our products with microservice architectures. However, since this architecture has many benefits, we need to revisit the way we enable developers to perform more comprehensive testing before pushing their changes into the production build pipeline. We have demonstrated a simple use case of using docker compose to perform this task. In creating a single, shareable representation of the production setup, we can keep developers moving forward and reduce the overall number of bugs merged into mainline code.